
🔍 在数据碎片化时代,Data Extractor 以跨源智能抓取引擎与零代码清洗能力重新定义信息获取效率。作为专业级Mac数据提取工具,它突破传统爬虫工具的技术门槛,深度融合网页结构识别、文档语义解析与数据库直连技术,支持从PDF报表到动态网页的50+数据源类型。其 AI字段定位系统 可自动学习数据结构规律,让非技术用户也能精准抽取目标信息,成为分析师、研究员的效率倍增器。
✨ 核心功能特色
✅ 全源数据捕获:
▪️ 网页:处理JavaScript渲染页面,绕过反爬机制,自动翻页抓取分页表格
▪️ 文档:解析PDF文字图层/扫描件OCR,保留原始表格结构与超链接
▪️ 数据库:直连MySQL/PostgreSQL执行SQL查询,结果集直接导出
▪️ API:可视化配置OAuth认证,JSON/XML数据自动扁平化
✅ 智能字段建模:
▪️ 圈选数据区域自动生成XPath/CSS选择器
▪️ 正则表达式测试器实时预览匹配结果
▪️ 关联字段跨页合并(如商品详情+评论)
✅ 自动化流水线:
▪️ 定时任务触发抓取(日/周/月循环)
▪️ 数据变化监控即时邮件告警
▪️ 清洗规则链(去重/格式化/计算列)
✅ 企业级输出枢纽:
▪️ 导出CST/JSON/XLSX至指定文件夹
▪️ 直推Google Sheets/Airtable
▪️ Webhook触发Zapier自动化流程
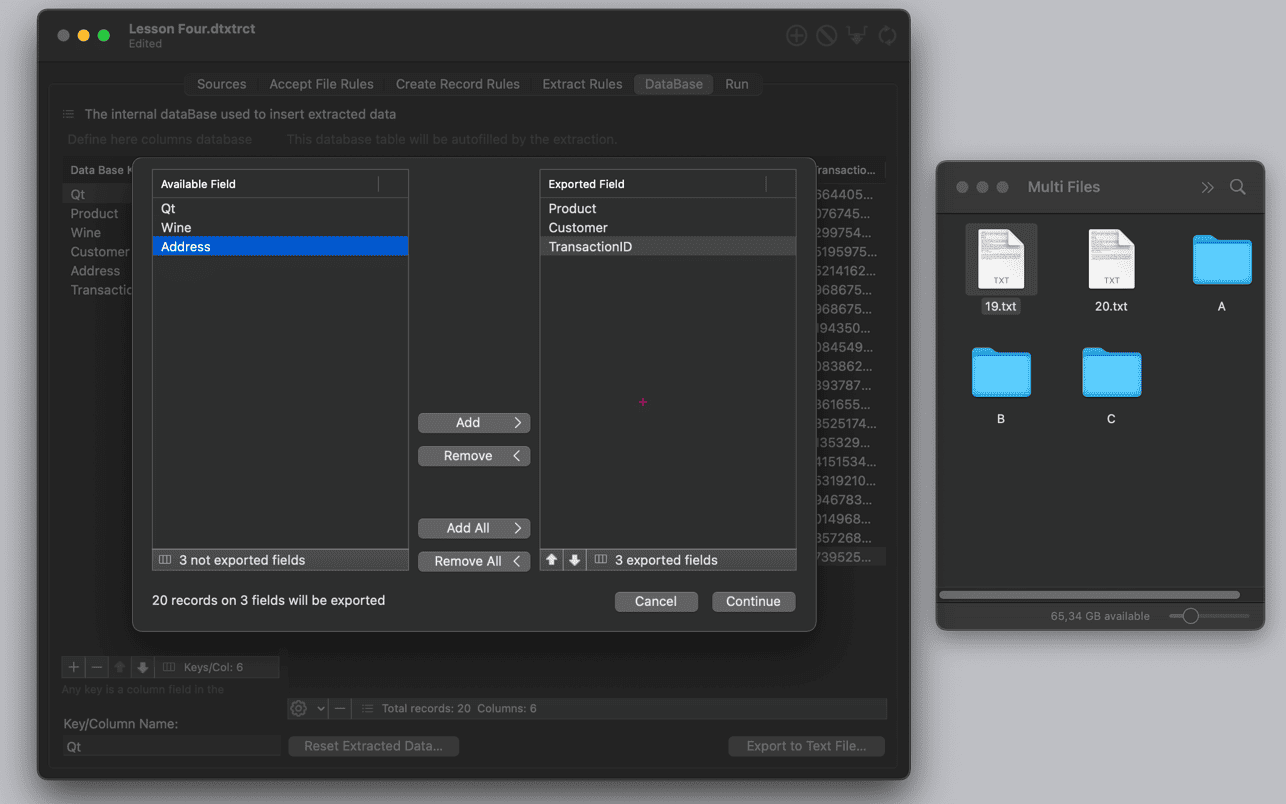
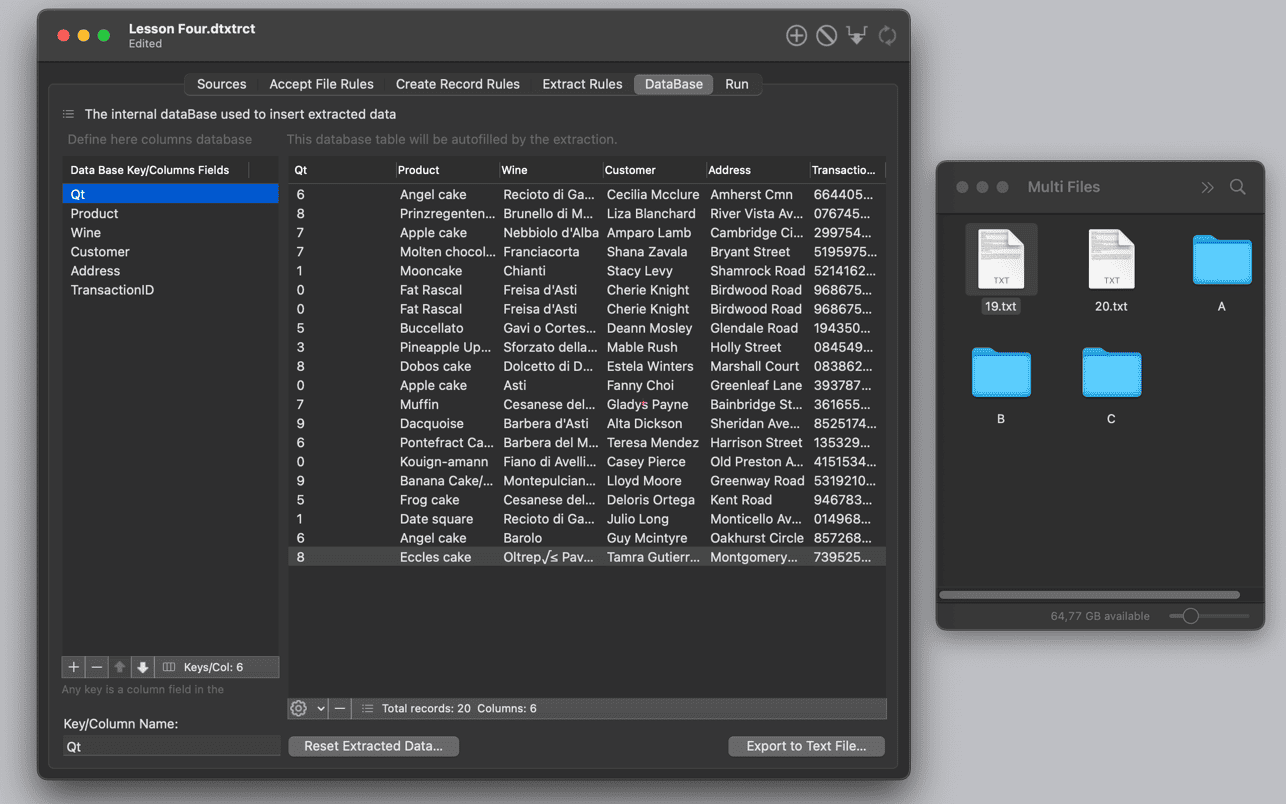
📊 场景化功能应用
电商运营🛒:监控竞品价格波动,自动抓取Amazon商品页SKU数据,差价超阈值触发企业微信告警
学术研究📚:批量提取学术期刊PDF中的实验数据表,合并为结构化数据集供SPSS分析
财务审计💰:抓取银行流水网页生成交易分类报告,异常流水自动标红导出Excel模板
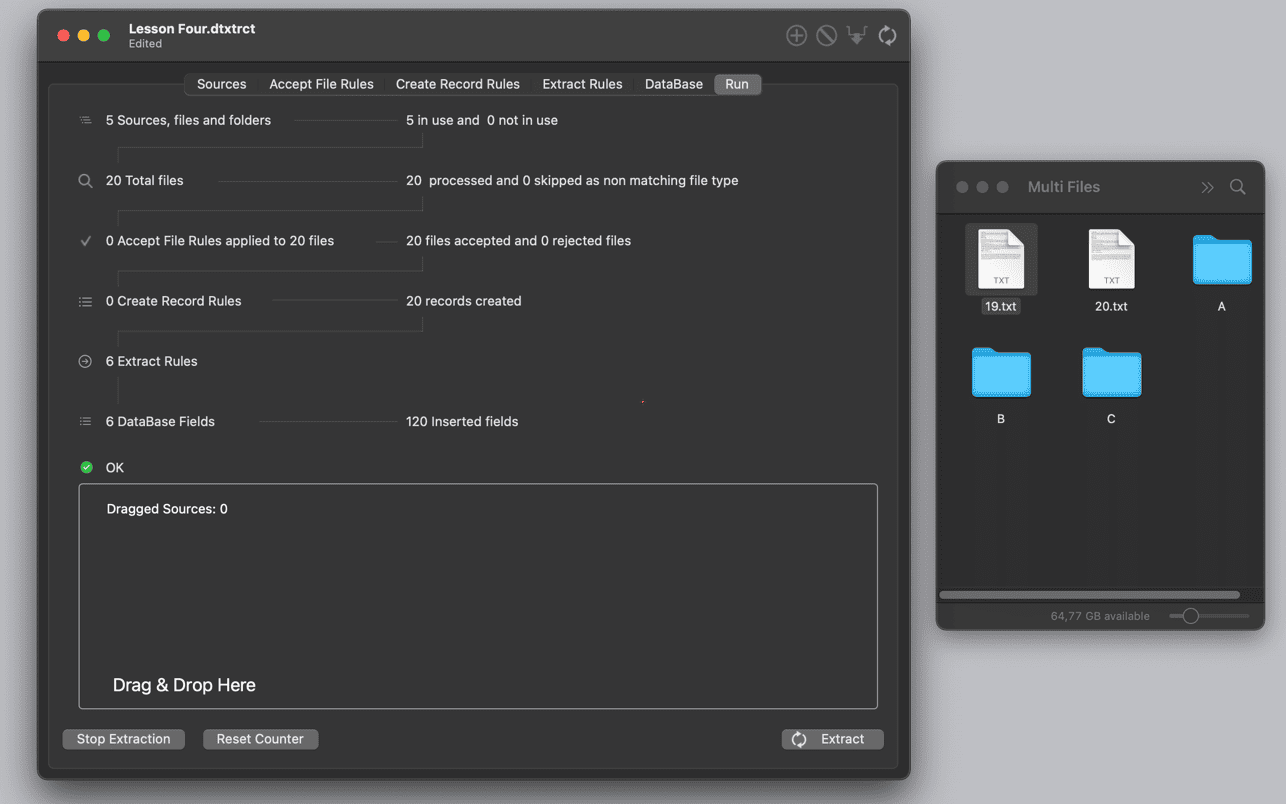
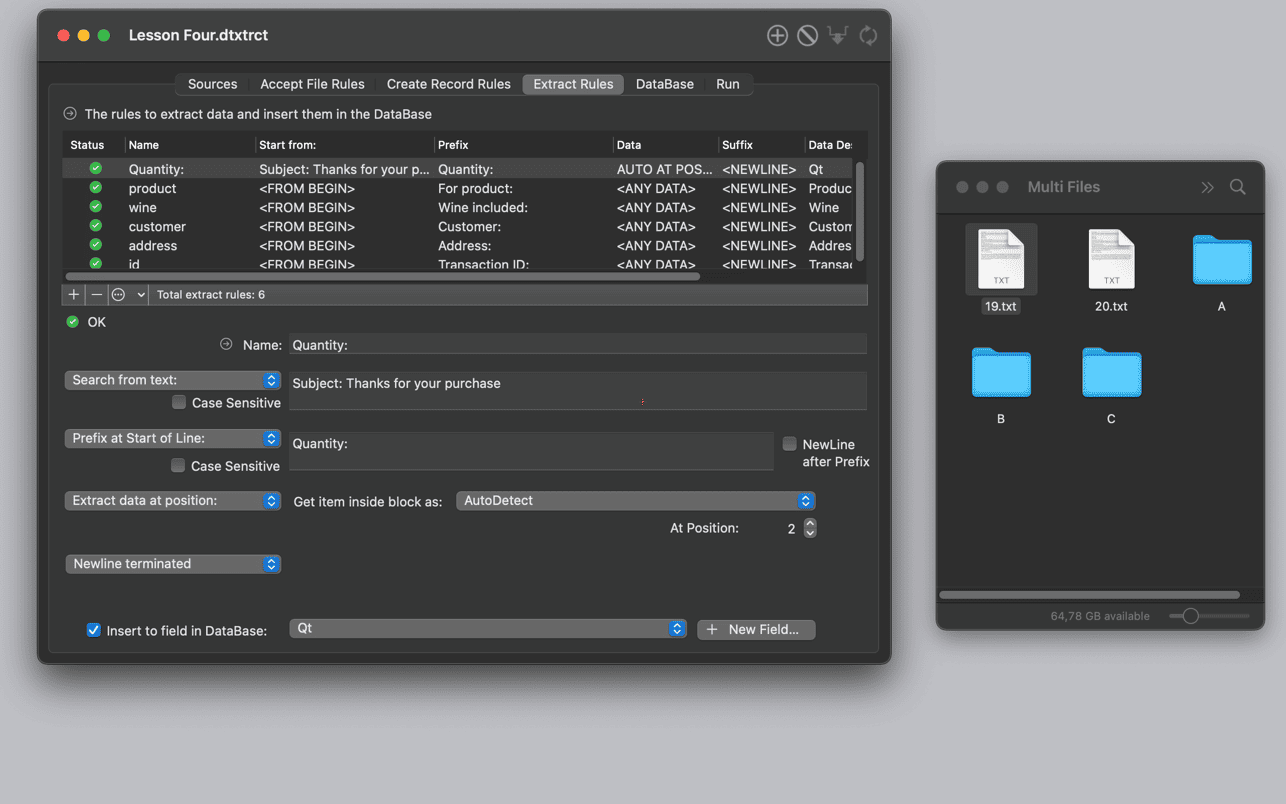
作为专业级Mac数据提取工具的标杆,Data Extractor的 本地化数据处理(敏感数据不出设备)与 SOC2合规架构,满足金融/医疗行业安全要求。其 增量抓取模式 仅采集变更数据,较传统方案减少90%网络流量,为追求效率与安全的Mac数据提取工具用户提供工业级解决方案。
💡小技巧:遇到动态加载表格时,开启 「智能滚动捕获」 模式(▣按钮),工具自动模拟鼠标滚动至页面底部;使用 CMD+Shift+E 一键测试字段提取规则,避免全量抓取后才发现数据错位!
许可协议:《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》

评论(0)